
爬虫调度篇[Web 漏洞扫描器]
0x00 前言
上一篇主要如何通过向浏览器页面注入 JavaScript 代码来尽可能地获取页面上的链接信息,最后完成一个稳定可靠的单页面链接信息抓取组件。这一篇我们跳到一个更大的世界,看一下整个漏扫爬虫的运转流程,这一篇会着重描写爬虫架构设计以及调度部分。
0x01 设计
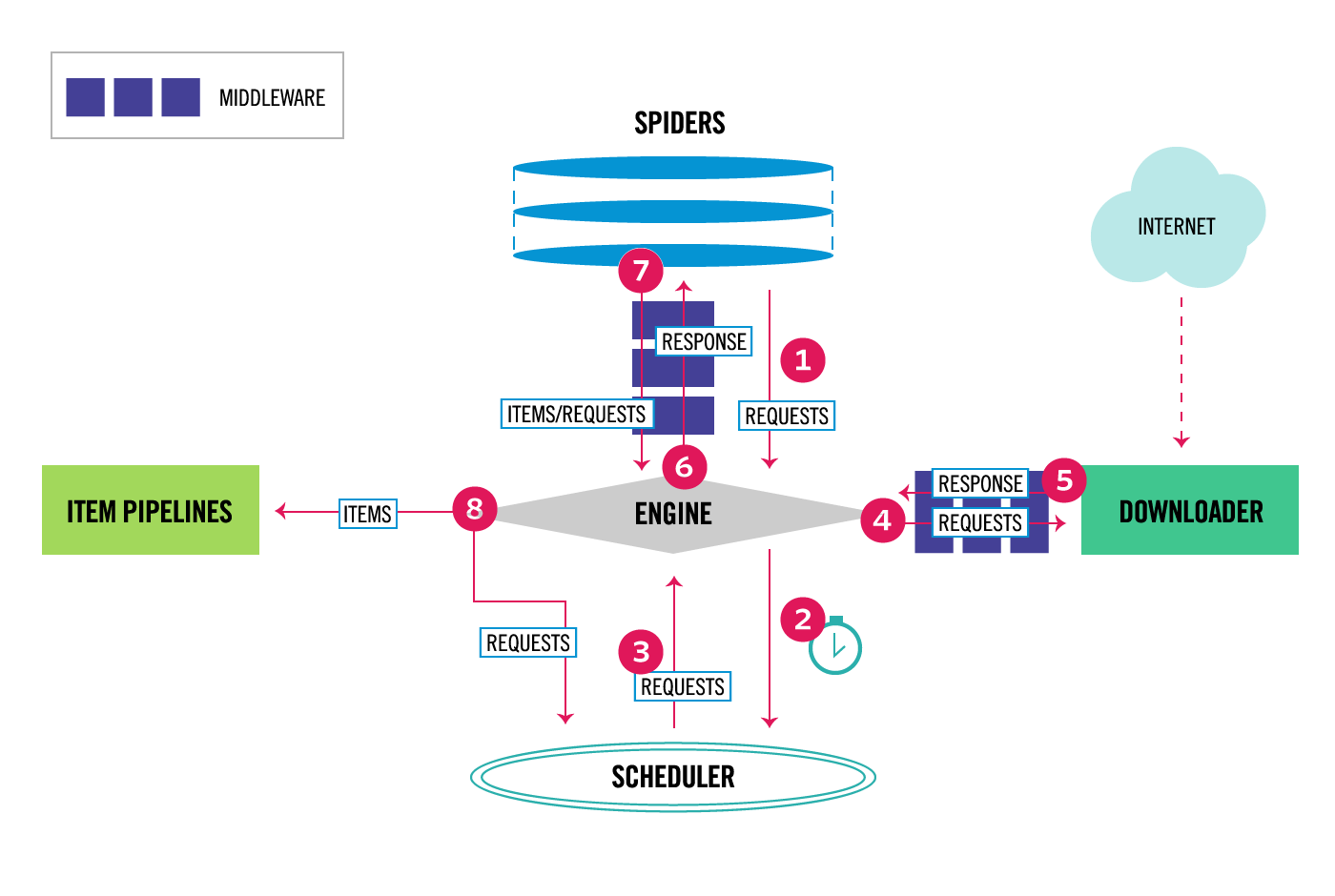
这张图片是不是很熟悉,其实这就是 Scrapy 的架构设计图,我们简单看一下这张图的流程:
Engine拿到RequestsEngine将Requests丢到Scheduler中,并向Scheduler请求下一个准备抓取的RequestScheduler返回下一个准备抓取的RequestEngine将Request丢到Downloader中,中途经过Downloader Middlewares处理Downloader处理Request产生Response返回给Engine,中途经过Downloader Middlewares处理Engine将Response丢到Spider中,中途经过Spider Middleware处理Spider处理Response产生出item和新的Requests返回给Engine,中途经过Spider Middleware处理Engine将item丢到Item Pipelines处理,同时将Requests丢到Scheduler中- 重复 1-8 步骤,直到
Scheduler没有新的Requests
在整体架构上我直接参考了 Scrapy 的设计,只不过我实在受不了 Twisted 那种扭曲的写法,
所以直接换了个网络库重新造了个和 Scrapy 差不多的轮子,新的架构图如下:
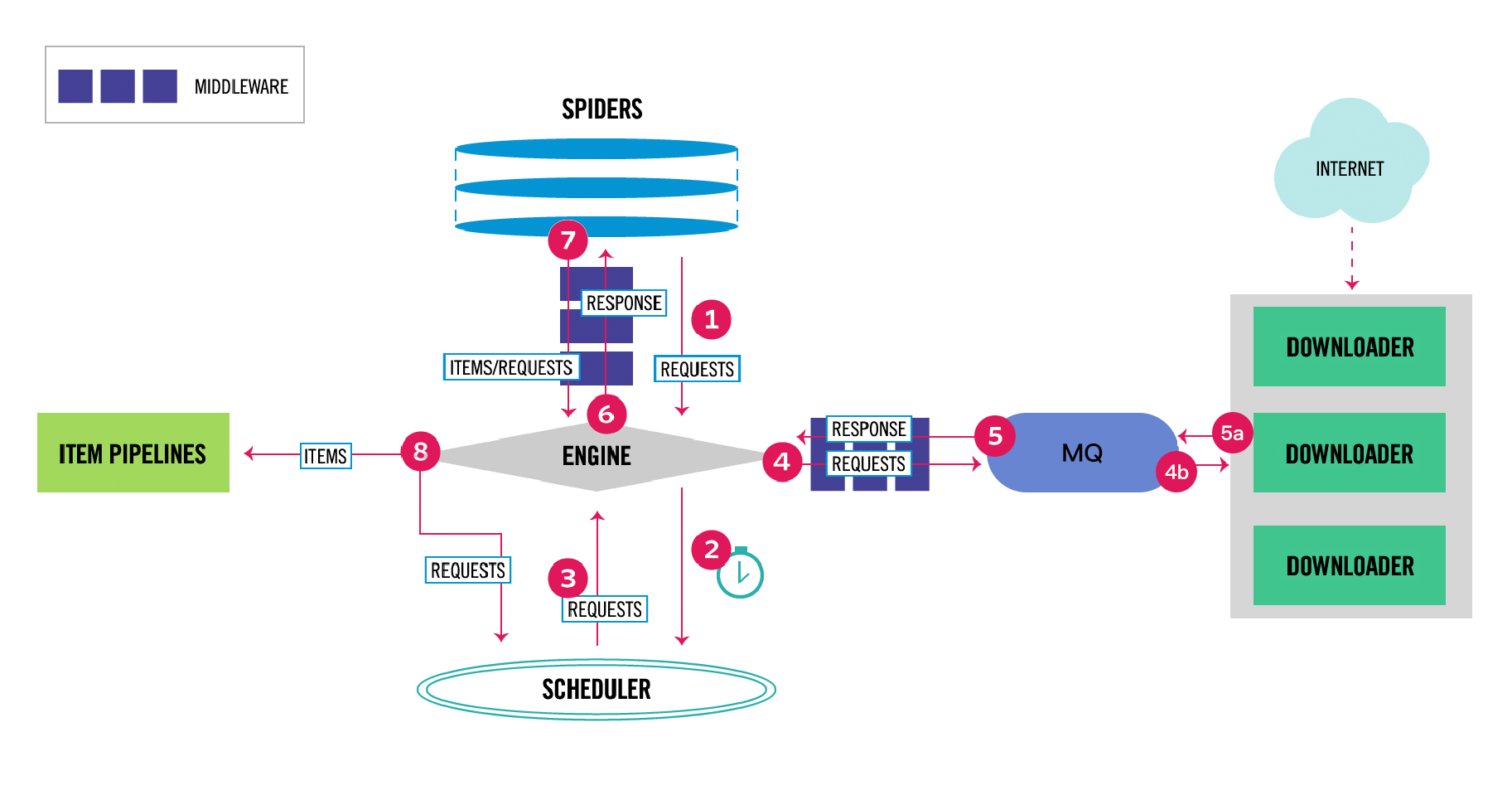
上面架构图中消息队列(MQ)左边的内部名为 CasterPy,右边的内部名为 CasterJS,
我们前两篇主要介绍的单页面链接信息抓取组件(CasterJS)就是上面的架构设计中的 Downloader,
我们的架构设计和 Scrapy 的区别是:
- 我们的
Downloader直接返回链接信息而不是返回响应内容 - 我们的
Downloader是分布式的,可部署在不同的服务器上 - 我们的
Engine通过消息队列与Downloader通信 - 我们的
Downloader针对同一个站点并发数始终为 1 - 我们的
CasterPy使用协程同时处理多个站点,可同时和多个Downloader进行通信
我们的 Spider 组件也只是简单的解析链接信息返回相对应的 item 和新的 Request,这部分没什么好讲的,
我们的 Engine 组件和 Scrapy 的也差不多,就是 Item、Request、Response 的搬运工,这部分也不用细讲,
至于 Item Pipelines,最后数据怎么存储、存储到哪里去,每家公司都有自己的想法(每家公司的想法差距都挺大的),这个就仁者见仁,
剩下就只有 Scheduler 了。
0x02 调度
Scheduler 决定了 Request 的优先级、去留,漏扫爬虫的 Scheduler 和普通爬虫的 Scheduler 最大的区别是如何决定 Request 的去留,也就是爬虫的去重问题。
去重真的是我在写漏扫爬虫除了 QtWebkit 之外最头疼的事情了。针对漏扫爬虫的去重,完全就没有什么比较好的公开的策略去处理,
老生常谈的 Bloom Filter 在漏扫爬虫中毫无用武之地。
普通爬虫一般来说只会丢弃非目标、已爬取的 Request,但在漏扫爬虫中完全不能只做这些,
因为这样不仅会浪费爬虫的资源,也会浪费后续检测的资源,所以我们需要自己造一个去重策略对 Request 进行更深层次的去重。
资源去重
我们在使用 Chromium 加载一个页面的时候,Chromium 会对网络资源做分类,这些分类主要有:

我们在之前注入的 JavaScript 代码在获取链接信息的时候也采取了这样的分类(虽然我之前没讲=。=),那很明显,我们只需要对 Doc 类型的 Request 进行再入 download 队列,其他资源都没必要再使用浏览器再下载渲染一遍。
链接去重
在最初的几年前在头疼去重这个问题的时候,剑心和我讨论的结果是可以把 request 中的参数分为 action 类型和 data 类型:
action类型: 对代码逻辑产生影响的参数data类型: 在代码中作为数据使用,一般不会影响到代码逻辑的参数
简单的讲,action 类型的参数就是语言 vm 中 opcode,data 类型就是语言 vm 中的操作数,
我们就是希望能够从 request 数据中分析出哪些是 action 类型的参数,哪些是 data 类型的参数,然后再进行去重。
我们看个简单的例子:
if ($_GET['a'] == 'create') {
mysql_query("INSERT INTO test VALUES ('$_GET['b']')", $conn);
}
其中 a 就是属于 action 类型的参数,因为 a 的值必须是 create 才会有数据库操作的逻辑。
b 属于 data 类型的参数,因为 b 的值无关紧要,不会影响到代码执行逻辑。
从代码中很容易分析出参数的类型,可是仅仅从 url 中怎么区别参数类型呢? 这个时候我们就需要从开发人员写代码的心理去推测参数类型了。
首先一般开发人员不会使用中文作为 action 类型参数的值,很难想象会有人这样写代码:
if ($_GET['a'] == '创建') { /* do create stuff */}
所以带中文字符的参数,可以直接被认为是 data 类型的参数。
其次一般开发人员的不会使用超过 2 位的纯数字作为 action 类型的值:
if ($_GET['a'] == '87') { /* do create stuff */ }
else if ($_GET['a'] == '9527') { /*do delete stuff */ }
再次一般开发人员也不会使用 HASH/UUID 值作为 action 类型的值:
if ($_GET['a'] == 'f95df1d4d3c89392f1fd920787bb7303') {}
else if ($_GET['a'] == 'f95df1d4-d3c8-9392-f1fd-920787bb7303') {}
还记得上一篇我们提到自动化填写表单的时候,最好能够自定义输入的地方都填上带 casterjs 字符吗?
就是为了能够在这里直接区分出带 casterjs 值的参数都是 data 类型参数。
最后一般开发人员也不会使用 … (自由想象、发挥、总结规律)
其实我们这个过程就是在猜,猜测一个正常的开发人员的编码规范。 前期通过各种猜测,我们可以对下面这些类型的 url 简单去重:
http://fatezero.org/test?a=create&b=你好 |
因为上面的参数 b 被识别成 data 类型参数,所以理论上 b 的值被替换成什么都无所谓,
我们将 data 类型参数的值替换成 { { data }} 得到 “临时规则”:
http://fatezero.org/test?a=create&b={{data}} |
上面这些去重步骤仅仅是第一步,接下来我们还要考虑下面这种情况:
http://fatezero.org/test?a=create&b=halo |
通过第一步简单替换之后,得到 “临时规则”:
1. http://fatezero.org/test?a=create&b=halo
2. http://fatezero.org/test?a=create&b=hello
3. http://fatezero.org/test?a=create&b={{data}}
...
这样的结果我们并不是特别满意,但通过第一步简单替换也只能得到这样的结果了。但随着第三条 “临时规则” 命中的 url 越来越多,
我们就越有理由相信参数 b 就是 data 类型的参数,参数 a 就是 action 类型的参数,
所以刚刚得到的 “临时规则” 在命中次数达到我们所设定的一个阈值后,还可以变成 “最后规则” :
http://fatezero.org/test?a=create&b={%data%} |
上面这条就是去重过程中生成的去重 “最后规则”,根据这条 “最后规则” 我们又可以直接对下面的链接直接去重:
http://fatezero.org/test?a=create&b=nihao
http://fatezero.org/test?a=create&b=world
http://fatezero.org/test?a=create&b=create
“临时规则” 只有统计的作用,并不能参与去重复步骤,但是 “最后规则” 可以参与去重。就如同刚才所示,”临时规则” 可以发展成 “最后规则”。
在 Scheduler 去重中,我们最希望拿到的并不是 url,而是实时在变化的去重规则,通过越来越多的 url 生成越来越精准的去重规则,
再通过越来越精准的规则反过来再对以后以及之前的 url 进行去重,得到重复度越来越低的 url,这就是我们造的去重策略。
URL Rewrite 去重
前面我们根据猜测开发人员心理去制定去重策略,这里我们还需要继续猜测 URL Rewrite 配置人员的心理去完善我们的去重策略。
我们先看一下几种常规的 URL Rewrite 之后 url 的样子:
http://fatezero.org/view/123.html |
我们先假设上面的 view 就是我们所说的 action 类型参数,123 就是 data 类型参数,
针对 URL Rewrite 之后的 url,我们首先应该找到各个参数之间的间隔符号是什么,上面的例子中参数间隔符号分别是 /、-、_,
然后以根路径开始,用 1、2、3 顺序作为 key,对应 path 深度的值作为 value,最终还是可以直接转换成 key-value 格式:
http://fatezero.org/?1=view&2=123 |
最后还是通过之前的去重策略进行去重,发现了么,漏扫去重这块大多数时候都只能猜测,并没有一个万能的解决方法。
0x03 测试
经过简单的测试,在 2 核 4G 内存服务器上能同时跑 50 个 Chromium Tab,
在 4 核 8G 内存服务器上一个 CasterPy 能够同时跑 1000 个任务,
也就是说一台 CasterPy 服务器可以和 20 台 CasterJS 服务器构成一个小规模的爬虫。
如果任务并发数增加,那也得相对应增加 CasterPy 服务器的资源以及 CasterJS 服务器的数量了。
0x04 总结
至此,扫描器中爬虫部分就算简单地过了一遍,虽然讲得比较粗略,但不管怎么样也得切到下一个话题了。
下一篇我们讲一下 Web 漏洞扫描器中漏洞检测技巧部分。