
爬虫基础篇[Web 漏洞扫描器]
0x00 前言
Web 漏扫的爬虫和其他的网络爬虫的技术挑战不太一样,漏扫的爬虫不仅仅需要爬取网页内容、分析链接信息, 还需要尽可能多的触发网页上的各种事件,以便获取更多的有效链接信息。 总而言之,Web 漏扫的爬虫需要不择手段的获取尽可能多新的链接信息。
在这篇博客文章中,我打算简单地介绍下和爬虫浏览器相关内容,爬虫基础篇倒不是说内容基础,而是这部分内容在漏扫爬虫中的地位是基础的。
0x01 QtWebkit or Headless Chrome
QtWebkit or Headless Chrome, that is a question
QtWebkit 还是 Headless Chrome,我们一个一个分析。
QtWebkit
我们先说一下在漏扫爬虫和 QtWebkit 相关的技术:
- 使用 QtWebkit
- 使用 PhantomJS (基于 Qt 编写)
- 使用 PyQt (一个 Python 的 Qt bindings)
这也是我之前在 TangScan 调研 QtWebkit 系列的时候面对的技术,当时就首先就排除了 PyQt, 因为在 PyQt 中没有办法自定义 QPA 插件,如果不借用 xvfb, 是没法在没有 X Server 的服务器上跑起来的,本来 PyQt 已经够慢,再加上一个 xvfb,那就更慢了,所以直接排除 PyQt。
接着讨论 PhantomJS,PhantomJS 的优点是简单,不需要再次开发,直接使用 js 就可以操作一个浏览器, 所以 TangScan 内部的第一个版本也选择了 PhantomJS,但后面也发现了 PhantomJS 的不足。
首先 PhantomJS 可以使用 js 操作浏览器是个优点,但也必须多出一个 js context (QWebPage) 开销,而且有时候 js 的 callback 在一些情况下没有被调用。 其次我所需要的功能 PhantomJS 并没有提供,然而在 QtWebkit 中可以实现。
所以 TangScan 内部的第二版,我选择了使用 QtWebkit 来重新写一个类似 PhantomJS 的东西 (内部名为 CasterJS,AWVS 也是用 QtWebkit 写了个名为 marvin 的爬虫)。
但是直接使用 QtWebkit 还是有问题。
首先自从 Qt5.2 之后,对应的 WebKit 引擎就没有再更新过,别说支持 ES6 了,函数连 bind 方法都没有。
其次内存泄漏问题严重,最明显的情况就是设置默认不加载图片 QWebSettings::AutoLoadImages 的时候,内存使用率蹭蹭地往上涨。
最后也是最严重的问题,稳定性欠缺,也是自己实现了 CasterJS 之后才知道为什么 PhantomJS 上为什么会有那么多没处理的 issue,
这个不稳定的原因是第三方库不稳定 (老旧的 Webkit),自己还不能更换这个第三方库。
当时在 TangScan 的时候,就非常头疼这些明知道不是自己的锅、解决起来特麻烦、还必须得解决的问题。
所以如果没有其他选择,QtWebkit 忍一忍还是能继续使用下去,但是 Headless Chrome 出现了。
Headless Chrome
Chrome 的 Headless 模式在 2015-08 开始低调开发,2016-06 开始对外公开,2017-04 在 M59 上正式发布。
后来 PhantomJS 的开发者 Vitaly Slobodin 在 PhantomJS 邮件组发出了公告 [Announcement] Stepping down as maintainer, 听到这个消息我真的一点都不意外,在 TangScan 中,也是使用 Qt 从头开发起 CasterJS 的我来说, 已经受够了由于老旧的 Webkit 版本带来的各种 crash,内存泄漏,QtWebkit 这个坑实在是太坑了。
Vitaly Slobodin 在当时作为 PhantomJS 唯一的主要开发者, 面对着 PhantomJS 项目上那接近 2k 的 issue,心有余而力不足,而且 crash 问题占多数。 虽然说很多问题上游的 Webkit 已经解决了,但偏偏 Qt 一直绑定的都是 Webkit 几年前的版本, 所以 Vitaly Slobodin 就真的自个单独维护一个 QtWebkit 仓库,用于专门解决这样的问题。 但是作为 PhantomJS 唯一的开发者,既要开发新功能,又要持续跟进 QtWebkit 各种 BUG,力不从心。 然后雪上加霜的是 Qt 在 Qt 5.2 的时候宣布打算放弃 QtWebkit,不在进行更新,转而使用基于 Chromium 的 QWebEngine 取代 QtWebkit。 虽然后来 annulen 扛起了大旗,说要继续维护 QtWebkit,要从 Webkit 那里一点一点地更新代码, 但个人开发速度还是比不上一个团队。 这个时候 Headless Chrome 出来了,Vitaly Slobodin 在这个时候退出 PhantomJS 的开发是最好的选择了。
Headless Chrome 的出现也让我哭笑不得,哭的原因是因为 Headless Chrome 让我在 TangScan 开发的 CasterJS 变得毫无意义, 笑的原因因为 Headless Chrome 比其他基于 QtWebkit 写的 Headless 浏览器更快速、稳定、简单,让我跳出了 QtWebkit 这个坑。
夸了那么久 Headless Chrome 不过也并不代表 Headless Chrome 毫无缺点,
首先 Chrome 的 Headless 模式算是一个比较新的特性,一些功能还不算完善,只能等官方实现或者自行实现(比方说 interception 这个功能我就等了几个月)。
其次 CDP 所提供的 API 不稳定,还会存在变动(比方说 M63 和 M64 中 Network.continueInterceptedRequest 的变动),
所以在使用 Headless Chrome 的时候,一定要先确定的 Chrome 版本,再编写和 CDP 相关的代码。
当然我也发现有些公司内部扫描器在使用 IE,大致过了一遍代码,我个人并不觉得这是个好方案,所以我还是坚持使用 Headless Chrome。
0x02 小改 Chromium
OK,既然我们已经选定了 Headless Chrome,是不是可以撸起袖子开始干了呢,很抱歉, 目前 Headless Chrome 还是不太满足我们扫描器爬虫的需求,我们还需要对其代码进行修改。
官方文档很详细的介绍了如何编译、调试 Chromium,只要网络没问题(需翻墙),一般也不会遇到什么大问题,所以这里也没必要介绍相关知识。
hook location
我们先看一下这个例子
<script> |
这个场景面临的问题和 wivet - 9.php 有点儿类似: 怎么样把所有跳转链接给抓取下来?
可能熟悉 QtWebkit 的同学觉得直接实现 QWebPage::acceptNavigationRequest 虚函数就可以拦截所有尝试跳转的请求.
可能熟悉 Headless Chrome 的同学会说在 CDP 中也有 Network.continueInterceptedRequest 可以拦截所有网络请求,当然也包括跳转的请求。
但实际上这两种方法都只能获取到最后一个 /test3 链接,因为前面两次跳转都很及时的被下一次跳转给中断了,
所以更不会尝试发出跳转请求,类似 intercept request 的 callback 就不可能获取到所有跳转的链接。
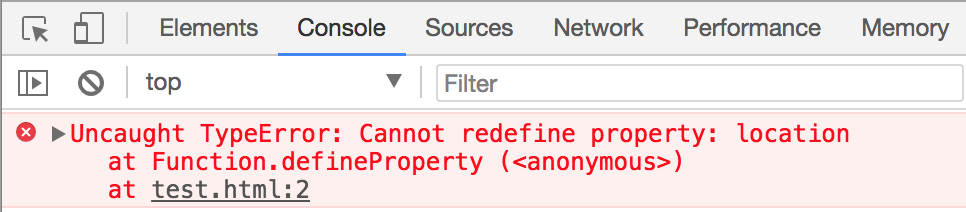
要是 location 能够使用 defineProperty 进行修改,那问题就简单多了。但是在一般的浏览器中 location 都是 unforgeable 的,也就是不能使用 defineProperty 进行修改,
不过现在 Chromium 代码在我们手上,所以完全可以将其修改为可修改的,直接修改 location 对应的 idl 文件即可:
--- a/third_party/WebKit/Source/core/frame/Window.idl |
--- a/third_party/WebKit/Source/core/dom/Document.idl |
测试代码:
<script>
Object.defineProperty(window, "location", {
set: function (newValue) {
console.log("new value: " + newValue);
},
get: function () {
console.log("get value");
return 123;
}
})
console.log(document.location);
console.log(window.location);
</script>
修改前:
修改后:
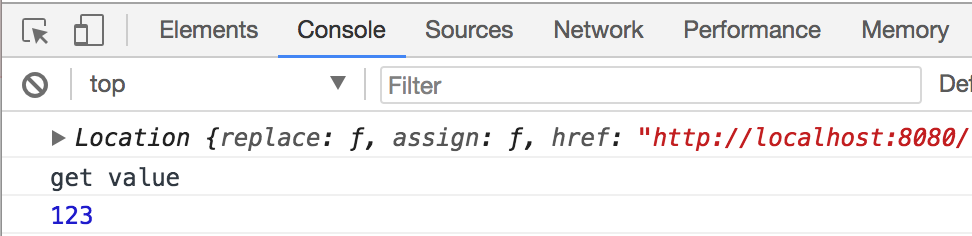
我之所以觉得伪造 location 这个特性很重要,是因为不仅仅在爬虫中需要到这个特性,在实现 DOM XSS 检测的时候这个特性也非常重要, 虽然说 Headless Chrome 官方文档上有提过将来可能会让用户可以自由 hook location 的特性 (官方文档上也是考虑到 DOM XSS 这块), 但过了将近一年的时间,也没有和这个特性的相关消息,所以还是自己动手丰衣足食。
popups 窗口
我们再来看看这个例子
<form action="http://www.qq.com" method="post" name="popup" target="_blank"> |
在 Headless Chrome 中会直接弹出一个 popups 窗口,CDP 只能禁止当前 page 跳转,但是没办法禁止新 page 创建,
在 QtWebkit 中并没有这样的烦恼,因为所有的跳转请求都由 QWebPage::acceptNavigationRequest 决定去留。
这个问题是 DM 同学提出来的,当时他和我讨论该问题。其实当时我也没有解决方法,于是我跑去 Headless Chrome 邮件组问了开发人员 Is there any way to block popups in headless mode?,
开发人员建议我先监听 Page.windowOpen 或 Target.targetCreated 事件,然后再使用 Target.closeTarget 关闭新建的 popups 窗口。
那么问题就来了,首先如果等待 page 新建之后再去关闭,不仅仅浪费资源去新建一个无意义的 page,而且 page 对应的网络请求已经发送出去了,如果该网络请求是一个用户退出的请求,那么事情就更严重了。 其次开发人员推荐的方法是没法区分新建的 page 是在某个 page 下新建的,还是通过 CDP 新建的。所以 Headless Chrome 开发人员的建议我并不是特别满意。
得,最好的办法还是继续修改代码,使其在 page 中无法新建 page:
--- a/third_party/WebKit/Source/core/page/CreateWindow.cpp |
--- a/third_party/WebKit/Source/core/page/CreateWindow.cpp |
忽略 SSL 证书错误
在 Headless Chrome 对外公开之后很长一段时间内,是没法通过 devtools 控制忽略 SSL 证书错误的,也没办法去拦截 Chrome 的各种网络请求。
直到2017-03 才实现了在 devtools 上控制忽略 SSL 证书错误的功能。
直到2017-06 才实现了在 devtools 可以拦截并修改 Chrome 网络请求的功能。
这两个特性对于扫描器爬虫来说非常重要,尤其是拦截网络请求的功能,可偏偏这两功能结合在一起使用的时候,就会出现 BUG, 在 puppeteer 上也有人提了 ignoreHTTPSErrors is not working when request interception is on, 直至现在(2018-03-05),Google 也并没有修复该 BUG,我还能说啥呢,还是自己动手,丰衣足食。
最简单的方法就是修改 Chromium 代码直接忽略所有的网站的 SSL 证书错误,这样也省了一个 CDP 的 callback,修改如下:
--- a/net/http/http_network_session.cc |
测试环境 badssl.com
在 Chromium 中还有一些其他可改可不改的地方,这里就不继续吐槽了。
0x03 总结
OK,折腾了那么久,终于把一个类似 wget 的功能实现好了(笑, 相对于我之前基于 QtWebkit 从头实现一个类似 PhantomJS 的 CasterJS 来说, 目前使用 Headless Chrome 稳定、可靠、快速,简直是漏扫爬虫的不二选择。
这篇博客就简单讲了一下和漏扫爬虫相关的 Headless 浏览器的知识,接下来就到了漏扫爬虫中最为重要的一点, 这一点也就决定了漏扫爬虫链接抓取效果是否会比其他扫描器好,能好多少,这都会在扫描器的下一篇文章中继续介绍。